
LLM
Always Under Construction!
99.7% Human Generated Content!
Using em-dash since 1998!
This page collects resources for using large language models (LLMs) in research and teaching -- building RAG pipelines, running local models, performing semantic search, and more.
LLMs have matured enormously since their introduction. Their most promising uses help us solve difficult but adjacent problems in research -- as tools for coding numerical solutions, performing exploratory data analysis, or organizing and cleaning datasets within an open source scientific computing stack built around Python and Jupyter notebooks. In the classroom, promises of individualized tutor chatbots abound, but LLMs can power locally run, teacher-facing analysis tools, too. (See Stan below!)
The transformer neural network architecture underlying LLMs is a transformative technology in what is, basically, an unexpected convergence of three things: the availability and maturity of highly parallelized processors optimized for matrix calculations (GPUs); the surprising (even to its inventors) performance of the transformer architecture; and large training datasets made possible by the maturity of the world wide web and broader internet. In many ways, our recent experiences with LLMs are analogous to the disruption that came with the introduction of the all-electronic general programmable computer in the late 1940s. Chemical engineers rapidly adopted that earlier technology to solve challenging modeling problems -- giving them solutions to partial differential equations and systems of these equations, especially, that were intractable or extremely inefficient before the development of machine computing. Specifically, LLMs give us a natural language interface to our computational tools.
One thing that's stayed with me as I've worked with LLMs is that engineers and scientists don't take technical solutions for granted. We generally like to "look under the hood" and see how things work. So, if you are interested in learning more about the technical underpinnings of LLMs, this page collects a few of those resources, too. (Spoiler alert: a Boltzmann-like distribution plays a central role in the architecture of GPTs.)
- Eric Furst
Recent work
Stan: An LLM-based thermodynamics course assistant
Emerging AI tools in education are largely student-facing: chatbots that answer questions, tutors that explain concepts, generators that produce practice problems. Instructor-facing tools -- tools that help faculty understand and improve their own teaching -- are far less developed. Stan is an attempt to fill that gap using many of the resources described on this page. Everything runs on local hardware -- a laptop for interactive queries, a GPU workstation for batch processing -- with no cloud APIs, no per-query fees, and full data privacy.
See the arXiv preprint for a full description and the code base on Github.
- arXiv preprint at arXiv:2603.04657
- Github repo: https://github.com/EntropicLearners/stan.git
CHEG 667-013 Chemical Engineering with Computers
In Spring 2025 and 2026, I taught a module on LLMs for the elective course, Chemical Engineering with Computers. The repositories below are a practical starting point for anyone wanting to run and experiment with LLMs, including an introduction for students to the CLI:
- A hands-on workshop on Large Language Models and machine learning for engineers. Learn how to train a GPT from scratch, run local models, build retrieval-augmented generation systems, then tie it back to underlying machine learning methods by implementing a simple neural network.
- A walkthrough of the Unix command line interface. Learn how to navigate the file system, manipulate files, search and filter text, manage processes, and write shell scripts — essential skills for any engineer working with computers.
Lecture slides: Attach:cheg667_013_llm_2025.pdf
Talks on LLMs
- Winter Research Review, January 2025
- Chemistry Biology Interface program's annual retreat, July 29, 2025
Hacking with LLMs
These tutorials are included in the hands-on LLM workshop above.
Running LLMs Locally -- Quick Start
Inference -- the text generation we experience with LLMs -- is not terribly computationally expensive. (The main and highly publicized energy use in these models comes with training them.) Capable models in the 7-8 billion parameter range can be run on consumer grade laptops and desktops. One of the fastest paths to running a local LLM is Ollama. Once installed, a single command pulls and runs a model:
ollama run gemma4:e4b
See the full Ollama entry in Access Models and Tools below, and the course handouts for step-by-step walkthroughs.
Build a RAG!
One of the interesting applications of transformers is the ability to catalog and search text semantically. In retrieval augmented generation (RAG) a body of text is used to construct a vector store -- chunks of text that are encoded in the abstract vector space of a sentence transformer (or more technically, embedded using a sentence transformer). Similarly embedded queries can then be compared against the vector store to find matching text. The search isn't a literal one, but it captures the semantic similarity of the query and matching vectors. The text retrieved from this search is then passed to an LLM to generate the query output. RAG can be used for such a semantic search or to summarize the retrieved documents. It also provides a way of introducing specific information an LLM can draw from outside of fine tuning a model.
- See the detailed walk through: RAG
- Code repo: https://furst.group/git/furst/rag-demo
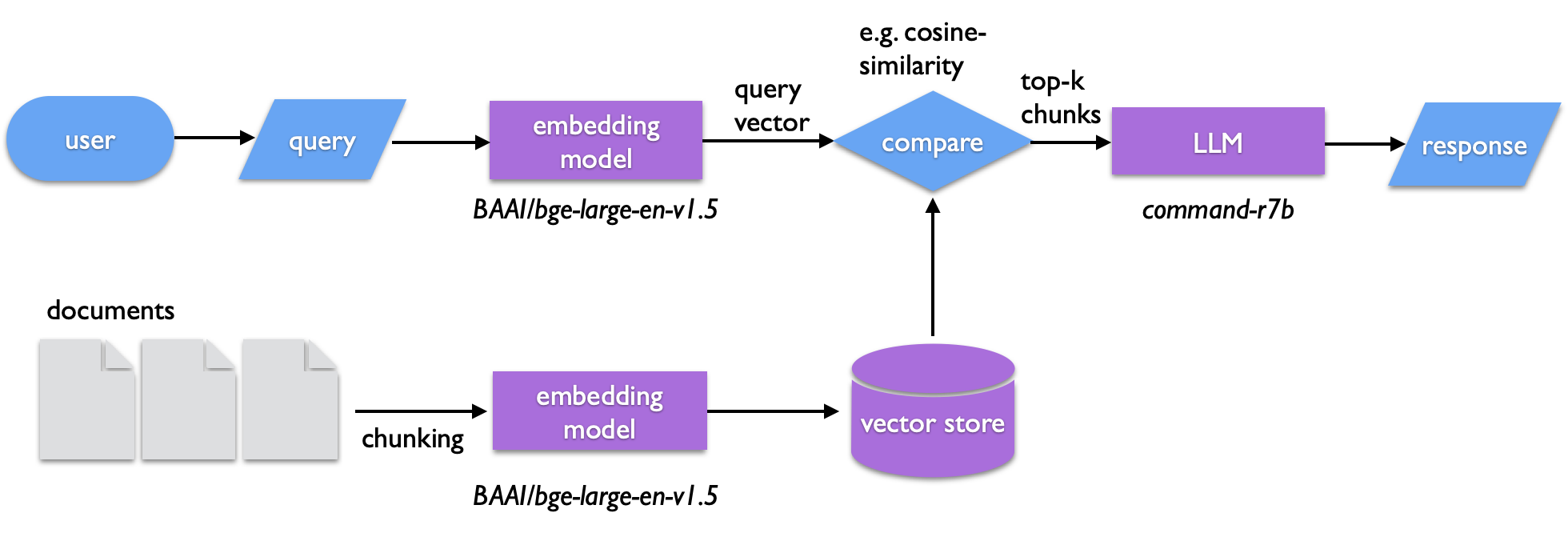
LLMs on the CLI
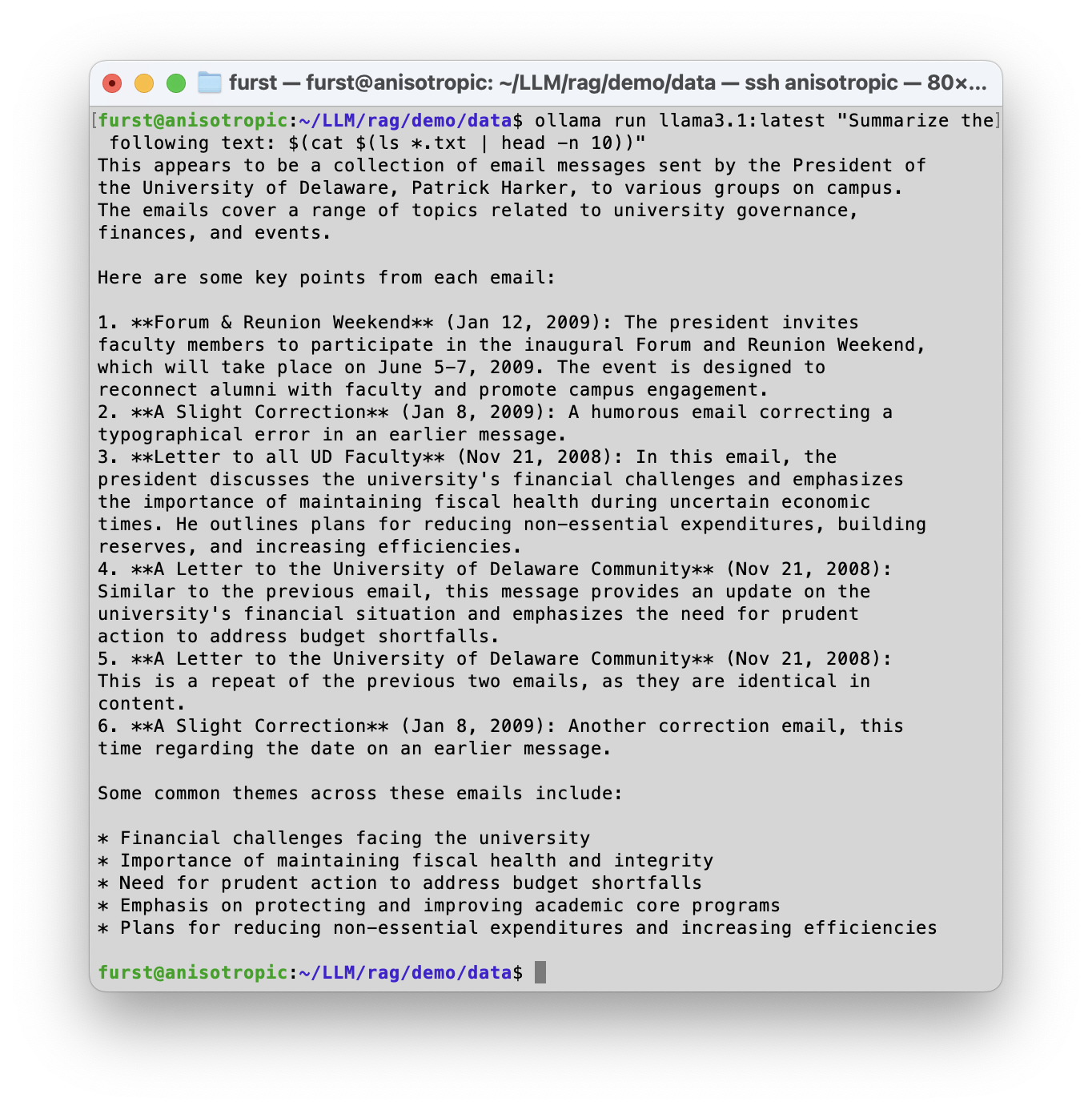
Need to summarize text, but don't want to share it with OpenAI or some other business with nebulous and ever-shifting data privacy policies? Local models can handle summarization tasks directly from the command line interface, enabling you to harness search and processing in conjunction with unix commands on macOS, Linux, etc.
- Examples and walkthrough: ollamacli
Semantic Search
Build a semantic search over a personal archive and a collection of clippings. It uses vector embeddings and a local LLM to find and synthesize information across 1800+ dated text entries spanning 2000-2025, plus a library of PDFs, articles, and web saves. You can test it against the ChatGPT API (or other cloud provider) or run completely local embedding and inference.
- See the code repo at https://furst.group/git/furst/ssearch
Access Models and Tools
Frameworks and Code
- Ollama -- https://ollama.com
- LlamaIndex -- https://docs.llamaindex.ai/en/stable/
ollama): https://docs.llamaindex.ai/en/stable/getting_started/starter_example_local/
- LLaMa (Meta) -- https://llama.com
- llama.cpp -- https://github.com/ggerganov/llama.cpp
- NanoGPT (Andrej Karpathy) -- Github codebases
Other Resources
- Tiktokenizer -- https://tiktokenizer.vercel.app
- Swiss AI Initiative -- https://www.swiss-ai.org
Essential Background
TL;DR
Key References
- Attention Is All You Need -- the paper that introduced the transformer architecture.
Link: https://dl.acm.org/doi/10.5555/3295222.3295349
Link: https://arxiv.org/pdf/1409.0473
Link: https://openreview.net/pdf?id=Hyg0vbWC-
Link: https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
Link: https://dl.acm.org/doi/abs/10.5555/3495724.3495883
- Andrej Karpathy's NanoGPT video walks through building a GPT step-by-step in code:
https://www.youtube.com/watch?v=kCc8FmEb1nY
- Brendan Bycroft's LLM visualizer (showing multi-head attention and transformer layers):
https://bbycroft.net/llm
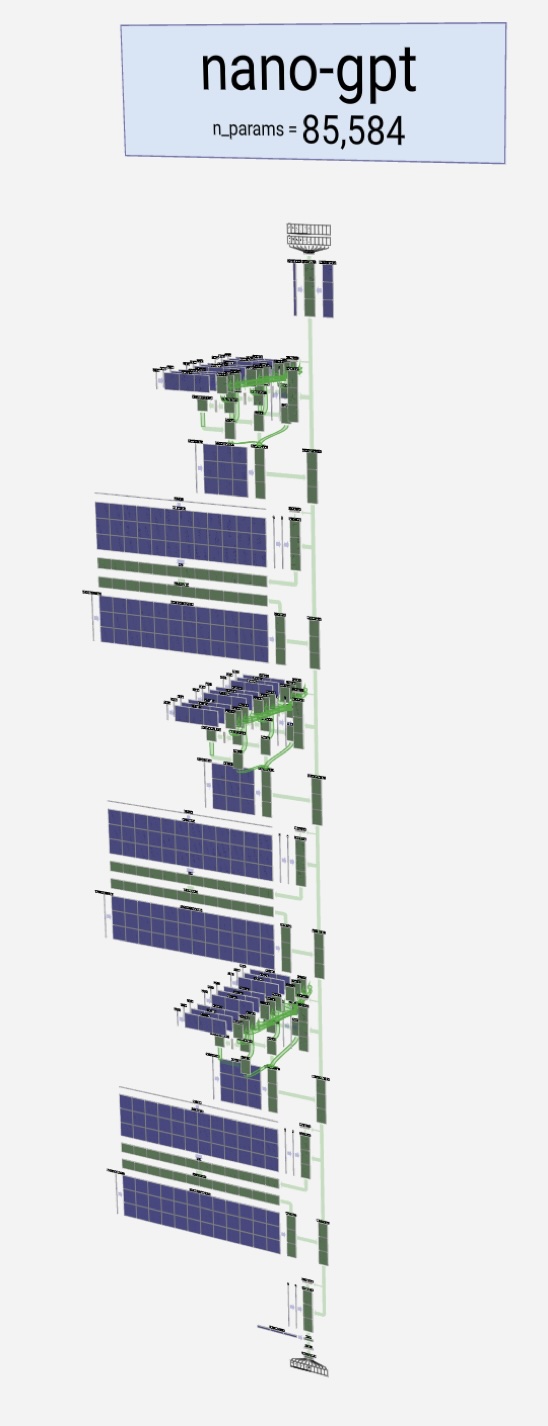
Left: the transformer (encoder and decoder) from Attention Is All You Need. Right: Karpathy's nanoGPT visualized with Bycroft's tool.
Related Reading (and Watching)
General interest
- Gideon Lewis-Kraus, "What Is Claude? Anthropic Doesn’t Know, Either," New Yorker, February 9, 2026.
Ethics of AI
- Louis Menand, "Is A.I. the Death of I.P.?", New Yorker, January 15, 2024.
- Grotti, Meg, et al. Summary and Recommendations from Spring 2024 Faculty Interviews in the Making AI Generative for Higher Education Project. University of Delaware, 2024.
Problems and Pitfalls
Melanie Mitchell reminds us that the solutions to alignment problems are not obvious, and that AI literacy is a commonsense first step:
https://doi.org/10.1126/science.aea3922
Energy and Resource Use
- IEA, Electricity 2025 -- growing electricity demand driven in part by data centers, EVs, and heat pumps:
https://www.iea.org/reports/electricity-2025 - Lawrence Livermore National Laboratory, Energy Flow Charts:
https://flowcharts.llnl.gov - Lawrence Berkeley Laboratory, 2024 United States Data Center Energy Usage Report:
https://doi.org/10.71468/P1WC7Q
Artistic and Literary Practices
When we first experiment with GPT-based LLMs, it's fascinating to experience a machine generating text with such high fidelity. But the interest in machine or "generative" text dates almost to the beginning of the modern computer era. Many experiments, spanning a context from AI research to artistic and literary practices, have been shared over the intervening decades.
- Christopher Strachey's program, often referred to as Love Letters, was written in 1952 for the Manchester Mark I computer. It is considered by many to be the first example of generative computer literature. In 2009, David Link ran Strachey's original code on an emulated Mark I, and Nick Montfort, professor of digital media at MIT, coded a modern recreation of it in 2014. The text output follows the pattern "you are my [adjective] [noun]. my [adjective] [noun] [adverb] [verbs] your [adjective] [noun]," signed by "M.U.C." for the Manchester University Computer. With the vocabulary in the program, there are over 300 billion possible combinations.
https://nickm.com/memslam/love_letters.html
Siobhan Roberts' article on Strachey's Love Letters: https://www.newyorker.com/tech/annals-of-technology/christopher-stracheys-nineteen-fifties-love-machine
David Link's Love Letters installation -- https://alpha60.de/art/love_letters/
My remix for the GPU era -- https://ef1j.org/glitched/love-llms/
- OUTPUT: An Anthology of Computer-Generated Text by Lillian-Yvonne Bertram and Nick Montfort is a timely book covering a wide range of texts, "from research systems, natural-language generation products and services, and artistic and literary programs." (Bertram, Lillian-Yvonne, and Nick Montfort, editors. Output: An Anthology of Computer-Generated Text, 1953–2023. The MIT Press, 2024.)
- Hallucinate This! by Mark Marino, https://markcmarino.com/chatgpt/
History of Computing
George Dyson's book Turing's Cathedral documents the history of the general, programmable electronic computer, including the explosion of applications that came with the introduction of this radical new technology, especially under the influence of John von Neumann.
- George Dyson, Turing's Cathedral: The Origins of the Digital Universe. Pantheon Books, 2012.
AI in the Physical Sciences
- Physics, AI, and the Future of Discovery -- AIP Foundation roundtable, April 2024. Prof. Jesse Thaler (MIT) segments:
- NIST Artificial Intelligence for Materials Science (AIMS) Workshop, July 9--10, 2025:
https://www.nist.gov/news-events/events/2025/07/artificial-intelligence-materials-science-aims-workshop - Microsoft Research AI for Science:
https://www.microsoft.com/en-us/research/lab/microsoft-research-ai-for-science/ - Meta FAIR:
https://ai.meta.com/research/
More Learning Resources
- Advanced Machine Learning -- https://www.youtube.com/@florian_marquardt_physics
- John Kitchin's pycse -- https://kitchingroup.cheme.cmu.edu/pycse/intro.html
More to come!

Earlier version of this page (January 2025): LLM2025