
You are an expert research assistant. You are given top-ranked writing excerpts (CONTEXT) and a user's QUERY.
Instructions:
- Base your response *only* on the CONTEXT.
- The snippets are ordered from most to least relevant—prioritize insights from earlier (higher-ranked) snippets.
- Aim to reference *as many distinct* relevant files as possible (up to 10).
- Do not invent or generalize; refer to specific passages or facts only.
- If a passage only loosely matches, deprioritize it.
Format your answer in two parts:
1. **Summary Theme**
Summarize the dominant theme from the relevant context in a few sentences.
2. **Matching Files**
Make a list of 10 matching files. The format for each should be:
<filename> -
<rationale tied to content. Include date or section hints if available.>
CONTEXT:
{context_str}
QUERY:
{query_str}
Now provide the theme and list of matching files.
Main /
RAG
NEW! Download the walkthrough repo at... https://furst.group/git/furst/rag-demo
One of the interesting applications of transformers is the ability to catalog and search text semantically. In retrieval augmented generation (RAG) a body of text is used to construct a vector store -- chunks of text that are encoded in the abstract vector space of a sentence transformer (or more technically, embedded using a sentence transformer). Similarly embedded queries can then be compared against the vector store to find matching text. The search isn't a literal one, but it captures the semantic similarity of the query and matching vectors. The text retrieved from this search is then passed to an LLM to generate the query output. RAG can be used for such a semantic search or to summarize the retrieved documents. It also provides a way of introducing specific information an LLM can draw from outside of fine tuning a model.
A basic RAG flow is illustrated below. Before running a user's query, a body of text ("documents") is chunked into smaller pieces that fit the context length of the embedding model. These embedded chunks become the vector store. When a query is run, the user's input text is embedded by the same model. The resulting vector is compared to those in the vector store, for instance by calculating the cosine similarity between the vectors. Vector store entries with the highest similarity are returned and are sent to a generating LLM to compose the response.
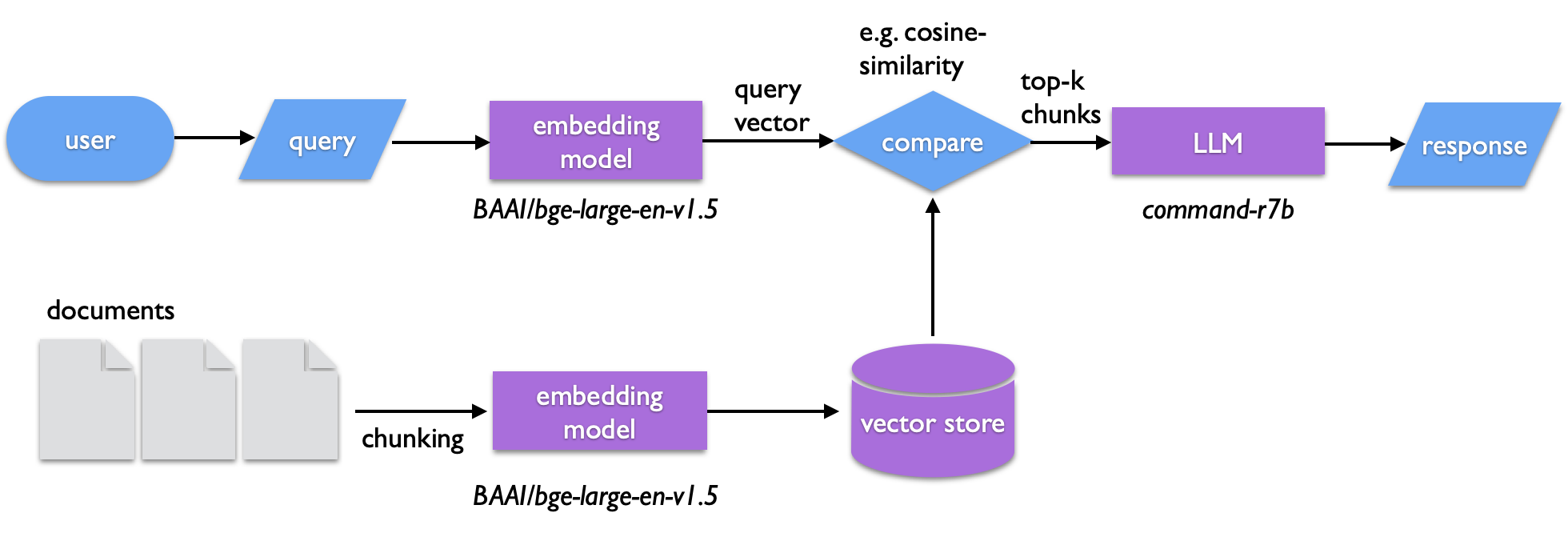
Here, I will describe building a simple RAG query pipeline using the llamaindex library. The advantage of this library is that it can more or less automatically handle the ingestion of documents and chunking into the vector store. The vector store will be a simple memory-based dictionary. This limits the size and number of documents we can store, but is sufficient for our demonstration. Larger and more sophisticated implementations use a database of some form to store and retrieve the vector store. Importantly, the pipeline will run solely using local models for the embedding and generation -- an approach that is ideal for working with private document collections.
Getting started
There are two main scripts: build.py and query.py. The first will build a vector store using an embedding model. The second will run simple queries against this model. I'm using an Apple MacBook M3 Pro with 18GB of memory. The Apple Silicon GPU has 18 cores and the CPU is a 12-core model, so the machine is a reasonably high-performance consumer laptop. You need a few GB of disk storage available for the models and text.
Before getting started, set up an environment. You'll need:
- A Python installation
ollama(the approach should accommodate a similar local model manager likellama.cpp, etc.)
If you haven't tried ollama, see this guide: Attach:Main.LLM2025/llm_2.pdf
Another hint: If you're on a mac like me, you may have had problems with macOS and getting python to work. My solution is to run it through homebrew (link). The executable (or a link to the executable) will be in something like /opt/homebrew/bin/python3.12.
Python virtual environment
We'll use a Python virtual environment (venv) for this example to manage the libraries and their dependencies. Create a working directory and install and activate venv:
$ python3 -m venv .venv $ source .venv/bin/activate ((.venv) ) $
We'll need the following libraries:
llama-index-core
llama-index-readers-file
llama-index-llms-ollama
llama-index-embeddings-huggingface
Use pip to install them in the venv:
((.venv) ) $ pip install llama-index-core llama-index-readers-file \ llama-index-llms-ollama llama-index-embeddings-huggingface
My command installed the following:
Python 3.12.11
lllama-index-core 0.13.1
llama-index-embeddings-huggingface 0.6.0
llama-index-instrumentation 0.4.0
llama-index-llms-ollama 0.7.0
llama-index-readers-file 0.5.0
llama-index-workflows 1.3.0
ollama 0.5.3
Download the LLM model
Using ollama, pull the LLM generating model with the command
$ ollama pull command-r7b
Alternatives to Cohere's command-r7b that I've tested include llama3.1:8B, deepseek-r1:8B, and gemma3:1b. All of these generate fairly quickly on my machine (the gemma models are very fast), but command-r7b is fine-tuned for RAG and tends to stick to the returned content better than the others in my tests. Be aware that the command-r7b license is Creative Commons Attribution-NonCommercial 4.0 International Public.
Download the embedding model
The Hugging Face Transformers library has the annoying behavior that it only temporarily caches the embedding model. This leads to a hang if there is no internet connection. Instead, download the model and cache it manually in a local directory with a short script:
from llama_index.embeddings.huggingface import HuggingFaceEmbedding embed_model = HuggingFaceEmbedding(cache_folder="./models",model_name="BAAI/bge-large-en-v1.5")
Here, we use the BAAI/bge-large-en-v1.5 model. I tested this and all-mpnet-base-v2, and got better performance from the BAAI model. It's a little larger and slower, though.
Importing documents
For this demo, I saved 294 email messages from the university president's emails to the university community as eml files. I first tried converting these using
$ textutil -convert txt *.eml
and moving the resulting .txt files to the ./data directory. The drawback here is that the text includes headers and MIME content. It turns out that this leads to a pretty long embedding run and a large vector store. So, instead I used a script to process the .eml files to strip out the body text:
"""
Simple script to convert .eml files to plain text files.
August 2025
"""
from email import policy
from email.parser import BytesParser
from pathlib import Path
from dateutil import parser
from dateutil import tz
eml_dir="eml" # files stored in ./eml directory
for eml_file in Path(eml_dir).glob("*.eml"):
with open(eml_file, "rb") as f:
msg = BytesParser(policy=policy.default).parse(f)
# Get metadata
subject = msg.get("subject", "No Subject")
date = msg.get("date", "No Date")
# Convert date to a safe format for filenames: YYYY_MM_DD_hhmmss
date = parser.parse(date)
if date.tzinfo is None:
date = date.replace(tzinfo=tz.tzlocal())
date = date.astimezone(tz.tzlocal())
msg_date = date.strftime("%d/%m/%Y, %H:%M:%S") # Format date for display
date = date.strftime("%Y_%m_%d_%H%M%S") # Format date for filename
# Prefer plain text, fallback to HTML
body_part = msg.get_body(preferencelist=('plain', 'html'))
if body_part:
body_content = body_part.get_content()
else:
body_content = msg.get_payload()
# Combine into a clean string with labels and newlines
text = f"Subject: {subject}\nDate: {date}\n\n{body_content}"
#out_file = eml_file.with_suffix(".txt")
out_file = Path(f"{eml_dir}/{date}.txt").open("w", encoding="utf-8")
out_file.write(text)
print(f"{msg_date}")
Simple script to convert .eml files to plain text files.
August 2025
"""
from email import policy
from email.parser import BytesParser
from pathlib import Path
from dateutil import parser
from dateutil import tz
eml_dir="eml" # files stored in ./eml directory
for eml_file in Path(eml_dir).glob("*.eml"):
with open(eml_file, "rb") as f:
msg = BytesParser(policy=policy.default).parse(f)
# Get metadata
subject = msg.get("subject", "No Subject")
date = msg.get("date", "No Date")
# Convert date to a safe format for filenames: YYYY_MM_DD_hhmmss
date = parser.parse(date)
if date.tzinfo is None:
date = date.replace(tzinfo=tz.tzlocal())
date = date.astimezone(tz.tzlocal())
msg_date = date.strftime("%d/%m/%Y, %H:%M:%S") # Format date for display
date = date.strftime("%Y_%m_%d_%H%M%S") # Format date for filename
# Prefer plain text, fallback to HTML
body_part = msg.get_body(preferencelist=('plain', 'html'))
if body_part:
body_content = body_part.get_content()
else:
body_content = msg.get_payload()
# Combine into a clean string with labels and newlines
text = f"Subject: {subject}\nDate: {date}\n\n{body_content}"
#out_file = eml_file.with_suffix(".txt")
out_file = Path(f"{eml_dir}/{date}.txt").open("w", encoding="utf-8")
out_file.write(text)
print(f"{msg_date}")
This generates 294 text files and just under a megabyte of text. The script includes the subject and date and uses the latter to save the filename. The filename and path become metadata in the vector store that's useful for search.
With the text files in ./data, we can build the vector store.
Building the vector store
The script build.py below will chunk the files in ./data and create a simple vector store in ./storage. By default, the routines preserve metadata for each node, which corresponds to the filename and file path. We'll use that information in our query, too.
build.py
# build.py
#
# Import documents from data, generate embedded vector store
# and save to disk in directory ./storage
#
# August 2025
# E. M. Furst
from llama_index.core import (
SimpleDirectoryReader,
VectorStoreIndex,
Settings,
)
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core.node_parser import SentenceSplitter
def main():
# Choose your embedding model
embed_model = HuggingFaceEmbedding(cache_folder="./models",model_name="BAAI/bge-large-en-v1.5")
# Configure global settings for LlamaIndex
Settings.embed_model = embed_model
# Load documents
documents = SimpleDirectoryReader("./data").load_data()
# Create the custom textsplitter
# Set chunk size and overlap (e.g., 256 tokens, 25 tokens overlap)
# see https://docs.llamaindex.ai/en/stable/api_reference/node_parsers/sentence_splitter/#llama_index.core.node_parser.SentenceSplitter
text_splitter = SentenceSplitter(
chunk_size=500,
chunk_overlap=50,
)
Settings.text_splitter = text_splitter
# Build the index
index = VectorStoreIndex.from_documents(
documents, transformations=[text_splitter],
show_progress=True,
)
# Persist both vector store and index metadata
index.storage_context.persist(persist_dir="./storage")
print("Index built and saved to ./storage")
if __name__ == "__main__":
main()
#
# Import documents from data, generate embedded vector store
# and save to disk in directory ./storage
#
# August 2025
# E. M. Furst
from llama_index.core import (
SimpleDirectoryReader,
VectorStoreIndex,
Settings,
)
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core.node_parser import SentenceSplitter
def main():
# Choose your embedding model
embed_model = HuggingFaceEmbedding(cache_folder="./models",model_name="BAAI/bge-large-en-v1.5")
# Configure global settings for LlamaIndex
Settings.embed_model = embed_model
# Load documents
documents = SimpleDirectoryReader("./data").load_data()
# Create the custom textsplitter
# Set chunk size and overlap (e.g., 256 tokens, 25 tokens overlap)
# see https://docs.llamaindex.ai/en/stable/api_reference/node_parsers/sentence_splitter/#llama_index.core.node_parser.SentenceSplitter
text_splitter = SentenceSplitter(
chunk_size=500,
chunk_overlap=50,
)
Settings.text_splitter = text_splitter
# Build the index
index = VectorStoreIndex.from_documents(
documents, transformations=[text_splitter],
show_progress=True,
)
# Persist both vector store and index metadata
index.storage_context.persist(persist_dir="./storage")
print("Index built and saved to ./storage")
if __name__ == "__main__":
main()
Besides the embedding model, the most important parameters are the chunk size and overlap. Chunk size is the number of tokens that will be embedded for each vector store entry. The overlap can help retain context across the vector store entries.
Running build.py takes a minute or so with this number and size of documents.
((.venv) ) $ python build.py Parsing nodes: 100%|███████████████████████████████████████████████████████████████████████| 294/294 [00:03<00:00, 79.53it/s] Generating embeddings: 100%|█████████████████████████████████████████████████████████████| 1098/1098 [01:13<00:00, 15.01it/s] Index built and saved to ./storage
You should see the files in the ./storage directory:
$ ls -lh storage total 58608 -rw-r--r--@ 1 furst staff 25M Aug 28 11:36 default__vector_store.json -rw-r--r--@ 1 furst staff 3.5M Aug 28 11:35 docstore.json -rw-r--r--@ 1 furst staff 18B Aug 28 11:35 graph_store.json -rw-r--r--@ 1 furst staff 72B Aug 28 11:36 image__vector_store.json -rw-r--r--@ 1 furst staff 92K Aug 28 11:35 index_store.json
A vector store Side Quest.
Running a query
Now we can run queries against the vector store. This simple example below uses the llamaindex library. It first loads the vector store as index, then converts this to a query engine class. The query method of the class passes the user input and does the rest -- it embeds the user input, calculates similarities against the vector store, and returns the best matching documents in the form of a response generated by the LLM. That final step takes the prompt, returned chunk text, and metadata and sends it to the LLM (command-r7b in this case) through ollama.
query.py
# query.py
# Run a querry on a vector store
#
# E. M. Furst, August 2025
from llama_index.core import (
load_index_from_storage,
StorageContext,
Settings,
)
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.ollama import Ollama
from llama_index.core.prompts import PromptTemplate
import os, time
#
# Globals
#
os.environ["TOKENIZERS_PARALLELISM"] = "false"
# Embedding model used in vector store (this should match the one in build.py or equivalent)
embed_model = HuggingFaceEmbedding(cache_folder="./models",model_name="BAAI/bge-large-en-v1.5")
# LLM model to use in query transform and generation
llm="command-r7b"
#
# Custom prompt for the query engine
#
PROMPT = PromptTemplate(
"""You are an expert research assistant. You are given top-ranked writing excerpts (CONTEXT) and a user's QUERY.
Instructions:
- Base your response *only* on the CONTEXT.
- The snippets are ordered from most to least relevant—prioritize insights from earlier (higher-ranked) snippets.
- Aim to reference *as many distinct* relevant files as possible (up to 10).
- Do not invent or generalize; refer to specific passages or facts only.
- If a passage only loosely matches, deprioritize it.
Format your answer in two parts:
1. **Summary Theme**
Summarize the dominant theme from the relevant context in a few sentences.
2. **Matching Files**
Make a list of 10 matching files. The format for each should be:
<filename> - <rationale tied to content. Include date if available.>
CONTEXT:
{context_str}
QUERY:
{query_str}
Now provide the theme and list of matching files."""
)
#
# Main program routine
#
def main():
# Use a local model to generate -- in this case using Ollama
Settings.llm = Ollama(
model=llm, # First model tested
request_timeout=360.0,
#context_window=8000,
)
# Load embedding model (same as used for vector store)
Settings.embed_model = embed_model
# Load persisted vector store + metadata
storage_context = StorageContext.from_defaults(persist_dir="./storage")
index = load_index_from_storage(storage_context)
# Build regular query engine with custom prompt
query_engine = index.as_query_engine(
similarity_top_k=15, # pull wide
#response_mode="compact" # concise synthesis
text_qa_template=PROMPT, # custom prompt
# node_postprocessors=[
# SimilarityPostprocessor(similarity_cutoff=0.75) # keep strong hits; makes result count flexible
# ],
)
# Query
while True:
q = input("\nEnter a search topic or question (or 'exit'): ").strip()
if q.lower() in ("exit", "quit"):
break
print()
# Generate the response by querying the engine
# This performes the similarity search and then applies the prompt
start_time = time.time() # seconds since epoch
response = query_engine.query(q)
end_time = time.time()
# Return the query response and source documents
print(response.response)
print("\nSource documents:")
for node in response.source_nodes:
meta = getattr(node, "metadata", None) or node.node.metadata
print(f"{meta.get('file_name')} {meta.get('file_path')} {getattr(node, 'score', None)}")
print(f"Elapsed time: {(end_time-start_time):.1f} seconds")
if __name__ == "__main__":
main()
# Run a querry on a vector store
#
# E. M. Furst, August 2025
from llama_index.core import (
load_index_from_storage,
StorageContext,
Settings,
)
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.ollama import Ollama
from llama_index.core.prompts import PromptTemplate
import os, time
#
# Globals
#
os.environ["TOKENIZERS_PARALLELISM"] = "false"
# Embedding model used in vector store (this should match the one in build.py or equivalent)
embed_model = HuggingFaceEmbedding(cache_folder="./models",model_name="BAAI/bge-large-en-v1.5")
# LLM model to use in query transform and generation
llm="command-r7b"
#
# Custom prompt for the query engine
#
PROMPT = PromptTemplate(
"""You are an expert research assistant. You are given top-ranked writing excerpts (CONTEXT) and a user's QUERY.
Instructions:
- Base your response *only* on the CONTEXT.
- The snippets are ordered from most to least relevant—prioritize insights from earlier (higher-ranked) snippets.
- Aim to reference *as many distinct* relevant files as possible (up to 10).
- Do not invent or generalize; refer to specific passages or facts only.
- If a passage only loosely matches, deprioritize it.
Format your answer in two parts:
1. **Summary Theme**
Summarize the dominant theme from the relevant context in a few sentences.
2. **Matching Files**
Make a list of 10 matching files. The format for each should be:
<filename> - <rationale tied to content. Include date if available.>
CONTEXT:
{context_str}
QUERY:
{query_str}
Now provide the theme and list of matching files."""
)
#
# Main program routine
#
def main():
# Use a local model to generate -- in this case using Ollama
Settings.llm = Ollama(
model=llm, # First model tested
request_timeout=360.0,
#context_window=8000,
)
# Load embedding model (same as used for vector store)
Settings.embed_model = embed_model
# Load persisted vector store + metadata
storage_context = StorageContext.from_defaults(persist_dir="./storage")
index = load_index_from_storage(storage_context)
# Build regular query engine with custom prompt
query_engine = index.as_query_engine(
similarity_top_k=15, # pull wide
#response_mode="compact" # concise synthesis
text_qa_template=PROMPT, # custom prompt
# node_postprocessors=[
# SimilarityPostprocessor(similarity_cutoff=0.75) # keep strong hits; makes result count flexible
# ],
)
# Query
while True:
q = input("\nEnter a search topic or question (or 'exit'): ").strip()
if q.lower() in ("exit", "quit"):
break
print()
# Generate the response by querying the engine
# This performes the similarity search and then applies the prompt
start_time = time.time() # seconds since epoch
response = query_engine.query(q)
end_time = time.time()
# Return the query response and source documents
print(response.response)
print("\nSource documents:")
for node in response.source_nodes:
meta = getattr(node, "metadata", None) or node.node.metadata
print(f"{meta.get('file_name')} {meta.get('file_path')} {getattr(node, 'score', None)}")
print(f"Elapsed time: {(end_time-start_time):.1f} seconds")
if __name__ == "__main__":
main()
The code creates index, which is a BaseIndex class object, from the vector store. Next, the method as_query_engine creates a query engine class object (BaseQueryEngine). The query engine is what processes a natural language query by retrieving relevant nodes, optionally post-processing them, and synthesizing a response using the LLM
( about query engines).
There are some commented out settings in the code above that can be interesting to experiment with. See the Exercises below.
Prompt
Llamaindex's default query engine prompt is
Context information is below.
---------------------
(context_str)
---------------------
Given the context information and not prior knowledge, answer the query.
Query: {query_str}
Answer:
---------------------
(context_str)
---------------------
Given the context information and not prior knowledge, answer the query.
Query: {query_str}
Answer:
You can inspect or update this prompt using the get_prompts and update_prompts methods on the query engine object.
In the query.py script, you can see that the LLM generation step uses on a custom prompt that helps direct the output:
Example output
Here's an example of a run. The user's query is "Find documents that highlight the excellence of the university." The query returns a summary and ten files that reference a number of expressions of the university's commitment to excellence.
The output here ends with a summary of the top 15 matching documents in the vector store. This output is what the LLM "sees" as the CONTEXT. It includes the file path, document title, and the similarity score. The search and generation run in just over a minute on battery power, which also accounts for some time to load the generating model in ollama.
((.venv) ) ~/Desktop/LLM/rag/demo/$ python query.py
Loading llama_index.core.storage.kvstore.simple_kvstore from ./storage/docstore.json.
Loading llama_index.core.storage.kvstore.simple_kvstore from ./storage/index_store.json.
Enter a search topic or question (or 'exit'): Find documents that highlight the excellence of the university.
## Summary Theme:
The dominant theme across the provided excerpts is the celebration of the University of Delaware's (UD) achievements, excellence, and impact on students, faculty, staff, alumni, and the community at large. The documents showcase UD's progress toward strategic goals like "Path to Prominence," its commitment to diversity and inclusion, student success, research advancements, and community engagement. They emphasize the university's positive influence on individuals and society while acknowledging the contributions of faculty, staff, students, alumni, and donors.
## Matching Files:
1. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2015_06_30_113132.txt - "Thank you for eight incredible years" by Patrick Harker, highlighting achievements like the STAR Campus transformation and recognition from the Carnegie Foundation.
2. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2008_05_30_105309.txt - Celebrates the first University of Delaware Forum, attended by nearly 1000 members to celebrate UD's history and future aspirations.
3. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2016_04_29_131912.txt - Request for volunteers as marshals or ushers at Commencement 2016, emphasizing UD's commitment to making the event a memorable and joyful experience.
4. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2023_06_09_160558.txt - Expresses gratitude for a successful academic year, highlighting events like the UDidIt! Picnic and Commencement, praising UD's people and commitment to students.
5. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2012_03_02_075111.txt - Employee Appreciation Day message from President Harker, thanking staff for their dedication and contributions to UD's mission and goals.
6. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2016_05_19_130501.txt - Introduces the Inclusive Excellence plan, emphasizing its importance for a world-class university experience and acknowledging UD's commitment to diversity and inclusion.
7. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2019_08_26_084103.txt - President Dennis Assanis' message highlighting UD's focus on academic excellence, inclusion, respect, and integrity.
Source documents:
2012_03_02_075111.txt /Users/furst/Desktop/LLM/rag/demo/data/2012_03_02_075111.txt 0.6562243911804028
2008_05_30_105309.txt /Users/furst/Desktop/LLM/rag/demo/data/2008_05_30_105309.txt 0.6559523386335219
2021_10_08_131418.txt /Users/furst/Desktop/LLM/rag/demo/data/2021_10_08_131418.txt 0.6549770885788161
2023_06_09_160558.txt /Users/furst/Desktop/LLM/rag/demo/data/2023_06_09_160558.txt 0.6491989841111314
2008_04_17_150323.txt /Users/furst/Desktop/LLM/rag/demo/data/2008_04_17_150323.txt 0.6482910934925187
2016_05_19_130501.txt /Users/furst/Desktop/LLM/rag/demo/data/2016_05_19_130501.txt 0.6398524233695277
2019_08_26_084103.txt /Users/furst/Desktop/LLM/rag/demo/data/2019_08_26_084103.txt 0.6386630039648108
2022_06_24_100128.txt /Users/furst/Desktop/LLM/rag/demo/data/2022_06_24_100128.txt 0.6380999350704643
2008_10_24_091230.txt /Users/furst/Desktop/LLM/rag/demo/data/2008_10_24_091230.txt 0.6378933724029956
2021_10_08_131418.txt /Users/furst/Desktop/LLM/rag/demo/data/2021_10_08_131418.txt 0.6325130393687082
2017_11_10_161522.txt /Users/furst/Desktop/LLM/rag/demo/data/2017_11_10_161522.txt 0.6304171872240688
2011_02_02_182102.txt /Users/furst/Desktop/LLM/rag/demo/data/2011_02_02_182102.txt 0.629765354967117
2012_09_20_180224.txt /Users/furst/Desktop/LLM/rag/demo/data/2012_09_20_180224.txt 0.6285979068144908
2015_06_30_113132.txt /Users/furst/Desktop/LLM/rag/demo/data/2015_06_30_113132.txt 0.628520367459588
2016_04_29_131912.txt /Users/furst/Desktop/LLM/rag/demo/data/2016_04_29_131912.txt 0.627290295095463
Elapsed time: 76.1 seconds
Loading llama_index.core.storage.kvstore.simple_kvstore from ./storage/docstore.json.
Loading llama_index.core.storage.kvstore.simple_kvstore from ./storage/index_store.json.
Enter a search topic or question (or 'exit'): Find documents that highlight the excellence of the university.
## Summary Theme:
The dominant theme across the provided excerpts is the celebration of the University of Delaware's (UD) achievements, excellence, and impact on students, faculty, staff, alumni, and the community at large. The documents showcase UD's progress toward strategic goals like "Path to Prominence," its commitment to diversity and inclusion, student success, research advancements, and community engagement. They emphasize the university's positive influence on individuals and society while acknowledging the contributions of faculty, staff, students, alumni, and donors.
## Matching Files:
1. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2015_06_30_113132.txt - "Thank you for eight incredible years" by Patrick Harker, highlighting achievements like the STAR Campus transformation and recognition from the Carnegie Foundation.
2. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2008_05_30_105309.txt - Celebrates the first University of Delaware Forum, attended by nearly 1000 members to celebrate UD's history and future aspirations.
3. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2016_04_29_131912.txt - Request for volunteers as marshals or ushers at Commencement 2016, emphasizing UD's commitment to making the event a memorable and joyful experience.
4. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2023_06_09_160558.txt - Expresses gratitude for a successful academic year, highlighting events like the UDidIt! Picnic and Commencement, praising UD's people and commitment to students.
5. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2012_03_02_075111.txt - Employee Appreciation Day message from President Harker, thanking staff for their dedication and contributions to UD's mission and goals.
6. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2016_05_19_130501.txt - Introduces the Inclusive Excellence plan, emphasizing its importance for a world-class university experience and acknowledging UD's commitment to diversity and inclusion.
7. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2019_08_26_084103.txt - President Dennis Assanis' message highlighting UD's focus on academic excellence, inclusion, respect, and integrity.
Source documents:
2012_03_02_075111.txt /Users/furst/Desktop/LLM/rag/demo/data/2012_03_02_075111.txt 0.6562243911804028
2008_05_30_105309.txt /Users/furst/Desktop/LLM/rag/demo/data/2008_05_30_105309.txt 0.6559523386335219
2021_10_08_131418.txt /Users/furst/Desktop/LLM/rag/demo/data/2021_10_08_131418.txt 0.6549770885788161
2023_06_09_160558.txt /Users/furst/Desktop/LLM/rag/demo/data/2023_06_09_160558.txt 0.6491989841111314
2008_04_17_150323.txt /Users/furst/Desktop/LLM/rag/demo/data/2008_04_17_150323.txt 0.6482910934925187
2016_05_19_130501.txt /Users/furst/Desktop/LLM/rag/demo/data/2016_05_19_130501.txt 0.6398524233695277
2019_08_26_084103.txt /Users/furst/Desktop/LLM/rag/demo/data/2019_08_26_084103.txt 0.6386630039648108
2022_06_24_100128.txt /Users/furst/Desktop/LLM/rag/demo/data/2022_06_24_100128.txt 0.6380999350704643
2008_10_24_091230.txt /Users/furst/Desktop/LLM/rag/demo/data/2008_10_24_091230.txt 0.6378933724029956
2021_10_08_131418.txt /Users/furst/Desktop/LLM/rag/demo/data/2021_10_08_131418.txt 0.6325130393687082
2017_11_10_161522.txt /Users/furst/Desktop/LLM/rag/demo/data/2017_11_10_161522.txt 0.6304171872240688
2011_02_02_182102.txt /Users/furst/Desktop/LLM/rag/demo/data/2011_02_02_182102.txt 0.629765354967117
2012_09_20_180224.txt /Users/furst/Desktop/LLM/rag/demo/data/2012_09_20_180224.txt 0.6285979068144908
2015_06_30_113132.txt /Users/furst/Desktop/LLM/rag/demo/data/2015_06_30_113132.txt 0.628520367459588
2016_04_29_131912.txt /Users/furst/Desktop/LLM/rag/demo/data/2016_04_29_131912.txt 0.627290295095463
Elapsed time: 76.1 seconds
The semantic search qualities are on full display in this example:
Enter a search topic or question (or 'exit'): Find documents that express happiness and joy.
**Summary Theme:**
The text collection emphasizes a sense of community, appreciation, and shared goals at the University of Delaware. It highlights the importance of collective effort and celebrates individual contributions to various events and projects. The tone is optimistic, with references to inspiration, success, and the positive impact of teamwork.
**Matching Files:**
1. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2009_06_05_114108.txt - This snippet celebrates Employee Appreciation Day at the University of Delaware, thanking employees for their contributions and encouraging them to express gratitude to colleagues.
2. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2016_04_29_131912.txt - Expresses appreciation for volunteers' efforts in organizing Commencement, emphasizing the joy and excitement of graduation.
3. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2023_06_09_160558.txt - Mentions an "amazing academic year" at UD with a picnic, Commencement ceremony, and Alumni Weekend, all celebrated with food, music, and camaraderie.
4. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2021_01_04_091941.txt - Includes a well-wishing message from Dennis Assanis to the university community, expressing happiness and gratitude for their hard work.
5. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2022_06_24_100128.txt - The president reflects on the success of Commencement 2022, thanking employees for their hard work and efforts to create memorable experiences.
6. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2008_05_30_105309.txt - A general appreciation message for attending the University of Delaware Forum, expressing gratitude for participants' involvement and providing feedback opportunities.
7. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2021_10_08_131418.txt - References a fundraising campaign called "Delaware First," focusing on engagement and the positive impact it will have on the university, which can be seen as contributing to overall happiness in the community.
8. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2018_01_03_171823.txt - This snippet emphasizes a sense of shared values and commitment at UD, wishing colleagues health, happiness, and success, which aligns with expressing joy and happiness in pursuit of common goals.
Source documents:
2020_01_02_113330.txt /Users/furst/Desktop/LLM/rag/demo/data/2020_01_02_113330.txt 0.6188836538820888
2022_04_22_090100.txt /Users/furst/Desktop/LLM/rag/demo/data/2022_04_22_090100.txt 0.6112736450684699
2009_06_05_114108.txt /Users/furst/Desktop/LLM/rag/demo/data/2009_06_05_114108.txt 0.6042930005223925
2016_04_29_131912.txt /Users/furst/Desktop/LLM/rag/demo/data/2016_04_29_131912.txt 0.6031501061958184
2023_06_09_160558.txt /Users/furst/Desktop/LLM/rag/demo/data/2023_06_09_160558.txt 0.6004969798693642
2008_04_17_150323.txt /Users/furst/Desktop/LLM/rag/demo/data/2008_04_17_150323.txt 0.5994836409847846
2021_01_04_091941.txt /Users/furst/Desktop/LLM/rag/demo/data/2021_01_04_091941.txt 0.5963489888390674
2022_06_24_100128.txt /Users/furst/Desktop/LLM/rag/demo/data/2022_06_24_100128.txt 0.5961222782911969
2008_05_30_105309.txt /Users/furst/Desktop/LLM/rag/demo/data/2008_05_30_105309.txt 0.5954753895833336
2021_10_08_131418.txt /Users/furst/Desktop/LLM/rag/demo/data/2021_10_08_131418.txt 0.5950278408766723
2021_10_08_131418.txt /Users/furst/Desktop/LLM/rag/demo/data/2021_10_08_131418.txt 0.5942690799493384
2021_10_08_131418.txt /Users/furst/Desktop/LLM/rag/demo/data/2021_10_08_131418.txt 0.5941805182776165
2012_03_02_075111.txt /Users/furst/Desktop/LLM/rag/demo/data/2012_03_02_075111.txt 0.5941681274749562
2018_01_03_171823.txt /Users/furst/Desktop/LLM/rag/demo/data/2018_01_03_171823.txt 0.5936713313411
2021_10_08_131418.txt /Users/furst/Desktop/LLM/rag/demo/data/2021_10_08_131418.txt 0.5928719211189324
Elapsed time: 75.3 seconds
**Summary Theme:**
The text collection emphasizes a sense of community, appreciation, and shared goals at the University of Delaware. It highlights the importance of collective effort and celebrates individual contributions to various events and projects. The tone is optimistic, with references to inspiration, success, and the positive impact of teamwork.
**Matching Files:**
1. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2009_06_05_114108.txt - This snippet celebrates Employee Appreciation Day at the University of Delaware, thanking employees for their contributions and encouraging them to express gratitude to colleagues.
2. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2016_04_29_131912.txt - Expresses appreciation for volunteers' efforts in organizing Commencement, emphasizing the joy and excitement of graduation.
3. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2023_06_09_160558.txt - Mentions an "amazing academic year" at UD with a picnic, Commencement ceremony, and Alumni Weekend, all celebrated with food, music, and camaraderie.
4. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2021_01_04_091941.txt - Includes a well-wishing message from Dennis Assanis to the university community, expressing happiness and gratitude for their hard work.
5. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2022_06_24_100128.txt - The president reflects on the success of Commencement 2022, thanking employees for their hard work and efforts to create memorable experiences.
6. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2008_05_30_105309.txt - A general appreciation message for attending the University of Delaware Forum, expressing gratitude for participants' involvement and providing feedback opportunities.
7. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2021_10_08_131418.txt - References a fundraising campaign called "Delaware First," focusing on engagement and the positive impact it will have on the university, which can be seen as contributing to overall happiness in the community.
8. file_path: /Users/furst/Desktop/LLM/rag/demo/data/2018_01_03_171823.txt - This snippet emphasizes a sense of shared values and commitment at UD, wishing colleagues health, happiness, and success, which aligns with expressing joy and happiness in pursuit of common goals.
Source documents:
2020_01_02_113330.txt /Users/furst/Desktop/LLM/rag/demo/data/2020_01_02_113330.txt 0.6188836538820888
2022_04_22_090100.txt /Users/furst/Desktop/LLM/rag/demo/data/2022_04_22_090100.txt 0.6112736450684699
2009_06_05_114108.txt /Users/furst/Desktop/LLM/rag/demo/data/2009_06_05_114108.txt 0.6042930005223925
2016_04_29_131912.txt /Users/furst/Desktop/LLM/rag/demo/data/2016_04_29_131912.txt 0.6031501061958184
2023_06_09_160558.txt /Users/furst/Desktop/LLM/rag/demo/data/2023_06_09_160558.txt 0.6004969798693642
2008_04_17_150323.txt /Users/furst/Desktop/LLM/rag/demo/data/2008_04_17_150323.txt 0.5994836409847846
2021_01_04_091941.txt /Users/furst/Desktop/LLM/rag/demo/data/2021_01_04_091941.txt 0.5963489888390674
2022_06_24_100128.txt /Users/furst/Desktop/LLM/rag/demo/data/2022_06_24_100128.txt 0.5961222782911969
2008_05_30_105309.txt /Users/furst/Desktop/LLM/rag/demo/data/2008_05_30_105309.txt 0.5954753895833336
2021_10_08_131418.txt /Users/furst/Desktop/LLM/rag/demo/data/2021_10_08_131418.txt 0.5950278408766723
2021_10_08_131418.txt /Users/furst/Desktop/LLM/rag/demo/data/2021_10_08_131418.txt 0.5942690799493384
2021_10_08_131418.txt /Users/furst/Desktop/LLM/rag/demo/data/2021_10_08_131418.txt 0.5941805182776165
2012_03_02_075111.txt /Users/furst/Desktop/LLM/rag/demo/data/2012_03_02_075111.txt 0.5941681274749562
2018_01_03_171823.txt /Users/furst/Desktop/LLM/rag/demo/data/2018_01_03_171823.txt 0.5936713313411
2021_10_08_131418.txt /Users/furst/Desktop/LLM/rag/demo/data/2021_10_08_131418.txt 0.5928719211189324
Elapsed time: 75.3 seconds
Remember, all of this is done locally on consumer-grade hardware without passing any information to a cloud service. Such local RAG implementations should be useful for organizing, searching, and summarizing sensitive or proprietary information in private document collections. It's pretty zippy on higher performance hardware, too. On a laboratory machine equipped with a single NVIDIA GeForce RTX 4090 GPU, a query will run in about 5-10 seconds -- roughly 10 times faster than my laptop.
Exercises
- Repeat the same query and note changes (and similarities) in the output.
- Try changing the embedding and generating models.
- Try changing the chunk size and overlap in
build.py. - Try changing the context length in
query.py. - Make changes to the prompt. Write a new prompt for different effects, possibly using a different generating model. (Here are two Examples.)
- The modest similarity scores in the examples above might improve by rewriting the query using strategies like HyDE (Hypothetical Document Embeddings).
- An alternative to query rewriting is to use a re-ranker in the pipeline.
Links and resources
- [[https://docs.llamaindex.ai/en/stable/] - llamaindex
- https://ollama.com - ollama
- https://nvlpubs.nist.gov/nistpubs/ir/2025/NIST.IR.8579.ipd.pdf - Developing the NCCoE Chatbot, NIST Internal Report, NIST IR 8579 ipd
- https://openwebui.com - Open WebUI, a turnkey and UI-driven local-first LLM for RAG workflows
- https://lem.che.udel.edu/git/furst/ssearch - More homebuilt RAG query scripts and tools that use reranking and a vector store database.
License
Copyright © 2025 by Eric M. Furst
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.