
LLM2025
2025 Winter Research Review Tech Talk... and More!
Always Under Construction!
99.9% Human Generated Content!
Presented on January 22, 2025 as the lunch talk for the Department of Chemical and Biomolecular Engineering Winter Research Review. In my talk, I discussed uses of large language models (LLMs), the underlying architecture of a generative pre-trained transformer (GPT), and basic aspects of the mechanics behind training and deploying LLMs.
This was on my mind: that engineers and scientists don't take technical solutions for granted. We generally like to "look under the hood" and see how things work. So, if you are interested in learning more about the technical underpinnings of LLMs, this page collects a few resources. The talk is largely inspired by the rapid adoption of LLMs to help us solve difficult but adjacent problems in our research: help with coding, semantic search, data organization, and other tasks.
In my talk, I didn't get into the details of how one goes from the single attention mechanism to "multi-head" attention, which is an important feature of LLM models. I also did not emphasize the step of fine-tuning models and how the basic generative text function of a GPT is built up into a powerful chatbot that many of us use. Those are topics worth exploring in greater depth.
Overall, I view GPTs as a transformative technology, in many ways analogous to the disruption that came with the introduction of the all-electronic general programmable computer in the late 1940s. Chemical engineers rapidly adopted that earlier technology to solve challenging modeling problems -- giving them solutions to partial differential equations and systems of these equations, especially, that were intractable or extremely inefficient before the development of machine computing. Specifically, LLMs will give us new ways to use our computational tools through natural language, help us to rapidly come up to speed in a new area, or quickly develop and analyze models and data with code.
I presented an updated and somewhat complementary talk for the Chemistry Biology Interface program's annual retreat on July 29, 2025:
- Eric Furst
Essential background
TL;DR
Referenced in the talk
These are several of the key references and resources that I cited in my talk.
- Attention Is All You Need -- this is the paper that introduced the transformer architecture. It's interesting to go back to the source. The transformer architecture discussed in the paper incorporates both encoder and decoder functions because the authors were testing its performance on machine translation tasks. Its performance in other natural language processing tasks, like language modeling and text generation in the form of unsupervised pretraining and autoregressive generation (as in GPT) was a major subsequent innovation.
Link: https://dl.acm.org/doi/10.5555/3295222.3295349
Link: https://arxiv.org/pdf/1409.0473
Link: https://openreview.net/pdf?id=Hyg0vbWC-
Link: https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
Link: https://dl.acm.org/doi/abs/10.5555/3495724.3495883
- Andrej Karpathy posts videos on Youtube that teach basic implementations of GPTs.
Karpathy's NanoGPT video shows you how to build a GPT, step-by-step: https://www.youtube.com/watch?v=kCc8FmEb1nY
- OpenAI 2023, GPT-4 Technical Report, arXiv:2303.08774
- Grotti, Meg, et al. Summary and Recommendations from Spring 2024 Faculty Interviews in the Making AI Generative for Higher Education Project. University of Delaware, Library, Museums and Press, Center for Teaching & Assessment of Learning, IT-Academic Technology Services, and School of Education, 2024.
- Applications in the physical sciences
I recommend to my students that they watch this roundtable discussion hosted by the AIP Foundation In April 2024, Physics, AI, and the Future of Discovery. In that event, Prof. Jesse Thaler (MIT) provided some especially insightful (and often humorous) remarks on the role of AI in the physical sciences -- including the April Fools joke, ChatJesseT. Below are links to his segments if you're short on time:
- Hallucinate This! by Mark Marino, https://markcmarino.com/chatgpt/
Access models and tools
The ecosystem of LLMs continues to grow. Many of us are familiar with proprietary LLMs through applications like OpenAI's ChatGPT, Anthropic's Claude, and Microsoft's Co-Pilot, but a number of open models are available to download and experiment on locally. Some models include information about the training dataset.
Frameworks and code
- Ollama -- https://ollama.com
- LLaMa (Meta) -- https://llama.com
- llama.cpp -- https://github.com/ggerganov/llama.cpp
- NanoGPT (Andrej Karpathy) -- Github codebases
- LlamaIndex -- https://docs.llamaindex.ai/en/stable/
ollama): https://docs.llamaindex.ai/en/stable/getting_started/starter_example_local/
Other resources
- Chatbot Leaderboard -- https://lmarena.ai
- Swiss AI Initiative -- https://www.swiss-ai.org
More learning resources
- Dive Into Deep Learning -- https://d2l.ai
- StatQuest -- https://statquest.org
- NLP Course For You -- https://lena-voita.github.io/nlp_course.html
- Advanced Machine Learning -- https://www.youtube.com/@florian_marquardt_physics
- Tiktokenizer -- https://tiktokenizer.vercel.app
- John Kitchin's pycse -- https://kitchingroup.cheme.cmu.edu/pycse/intro.html
Related reading
Ethics of AI
In discussions concerning the ethics of AI, and LLMs in particular, questions around at least two major topics frequently appear: intellectual property and resource use, including electricity and water. (I'd love to have more suggestions here as I work to expand this section.)
- Louis Menand discusses the relationship between AI and intellectual property in "Is A.I. the Death of I.P.?", New Yorker, January 15, 2024.
There are many articles in our daily news that cite the energy use of LLMs, some with sometimes dire predictions, such as the imminent collapse of the electrical grid. But how does LLM training and use compare to other digital activities, like search, streaming, and block chain services?
- The International Energy Agency's Electricity 2025 covers several relevant topics. For instance, growing electricity demand in the US and other mature economies is driven in part by data centers, but also from new electric vehicles, air conditioners, and heat pumps.
- Lawrence Livermore National Laboratory's Energy Flow Charts is a useful resource for understanding US energy use.
- Lawrence Berkeley Laboratory, 2024 United States Data Center Energy Usage Report
Problems and pitfalls in generative AI
Interfacing with computers through natural language is filled with exciting possibility. Yet, these emerging tools have pitfalls that include hallucinations and other problems of non-alignment. Melanie Mitchel reminds us that:
https://doi.org/10.1126/science.aea3922
History of computers and computational tools
- George Dyson's book Turing's Cathedral documents the history of the general, programmable electronic computer, including the explosion of applications that came with the introduction of this radical new technology, especially under the influence of John von Neumann.
Artistic and literary practices
When first experimenting with GPT-based LLMs, it's fascinating to experience a machine generating text with such high fidelity. But the interest in machine or "generative" text dates almost to the beginning of the modern computer era. Many experiments, spanning a context from AI research to artistic and literary practices, have been shared over the intervening decades. Mark Marino's book cited above is a recent example.
- Christopher Strachey's program, often referred to as Love Letters, was written in 1952 for the Manchester Mark I computer. It is considered by many to be the first example of generative computer literature. In 2009, David Link ran Strachey's original code on an emulated Mark I, and Nick Montfort, professor of digital media at MIT, coded a modern recreation of it in 2014. The text output follows the pattern "you are my [adjective] [noun]. my [adjective] [noun] [adverb] [verbs] your [adjective] [noun]," signed by "M.U.C." for the Manchester University Computer. With the vocabulary in the program, there are over 300 billion possible combinations.
https://nickm.com/memslam/love_letters.html
Siobhan Roberts' article on Strachey's Love Letters: https://www.newyorker.com/tech/annals-of-technology/christopher-stracheys-nineteen-fifties-love-machine
David Link's Love Letters installation -- https://alpha60.de/art/love_letters/
My remix for the GPU era -- https://ef1j.org/glitched/love-llms/
- OUTPUT: An Anthology of Computer-Generated Text by Lillian-Yvonne Bertram and Nick Montfort is a timely book covering a wide range of texts, "from research systems, natural-language generation products and services, and artistic and literary programs." (Bertram, Lillian-Yvonne, and Nick Montfort, editors. Output: An Anthology of Computer-Generated Text, 1953–2023. The MIT Press, 2024.)
More links
- Microsoft Research AI for Science
https://www.microsoft.com/en-us/research/lab/microsoft-research-ai-for-science/ - Meta FAIR
https://ai.meta.com/research/ - NIST Artificial Intelligence for Materials Science (AIMS) Workshop
CHEG 667-013
In the Spring 2025, I taught a module on LLMs for an elective course. Below are the course handouts. The first two cover LLMs, including running Andrej Karpathy's NanoGPT and local models using Ollama. The other two handouts are an introduction to command line interfaces.
- Attach:llm_1.pdf -- Large Language Models Part 1: NanoGPT
- Attach:llm_2.pdf -- Large Language Models Part 2: Running Ollama
- Attach:cli_1.pdf -- Command Line Interface Part 1
- Attach:cli_2.pdf -- Command Line Interface Part 2
Here are the lecture slides:
Hacking with LLMs
Build a RAG!
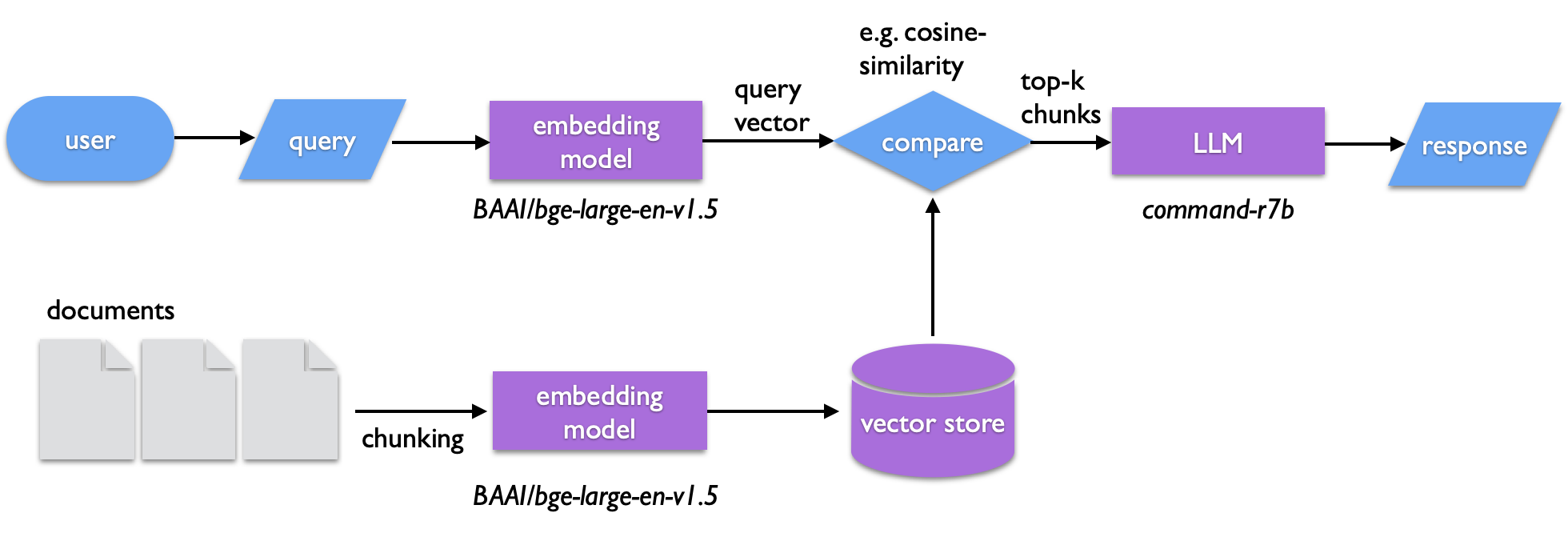
RAG stands for Retrieval Augmented Generation -- a way to harness LLMs to semantically search documents or summarize them.
- Check it out here >>> RAG
LLMs on the CLI
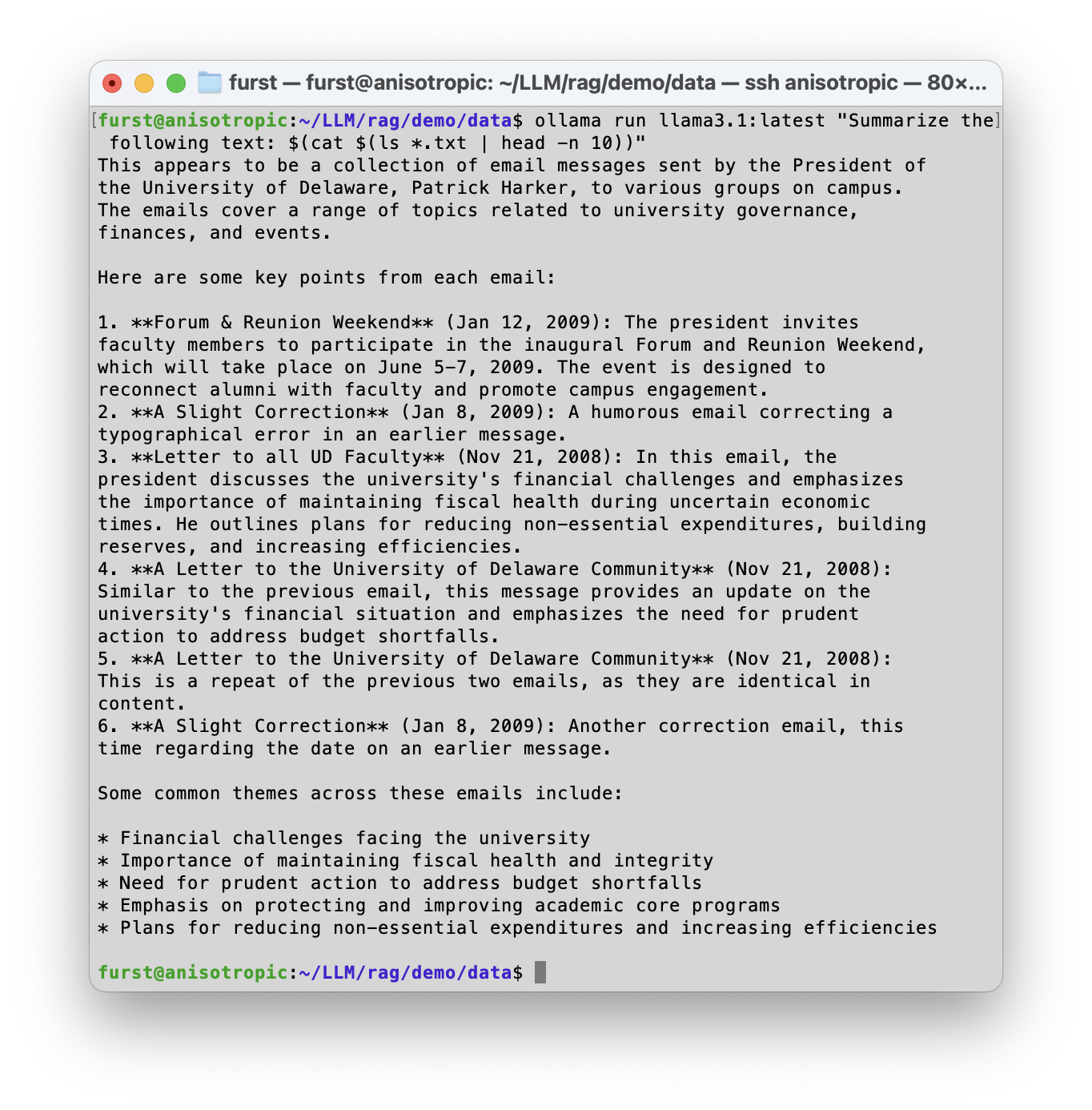
Need to summarize text, but don't want to share it with OpenAI or some other business with nebulous and ever-shifting data privacy policies and promises? Local models can handle summarization tasks directly from the command line interface, enabling one to harness search and processing in conjunction with unix commands on macOS, Linux, etc.
- Check it out! >>> ollamacli
For instructors
LLM performance in technical subjects
- In addition to the OpenAI GPT-4 Technical Report that evaluates the model's performance on standardized exams, the MIT Teaching + Learning Lab published this evaluation of ChatGPT-4's responses to thermodynamics problems:
https://tll.mit.edu/chatgpt-4-questions-from-a-materials-thermodynamics-course/
Course policies
Here is text that I published on our Fall 2024 CHEG 231 Canvas site: Using AI: tools, tips, and guidelines. Instructors: feel free to download the html and use it as a starting point for your own course. Suggestions for how to improve it are welcome!
Below on the left is a picture of the transformer (encoder and decoder) from Attention Is All You Need. The architecture varies from model to model. GPT-2 and GPT-3 changed the order of some calculations.
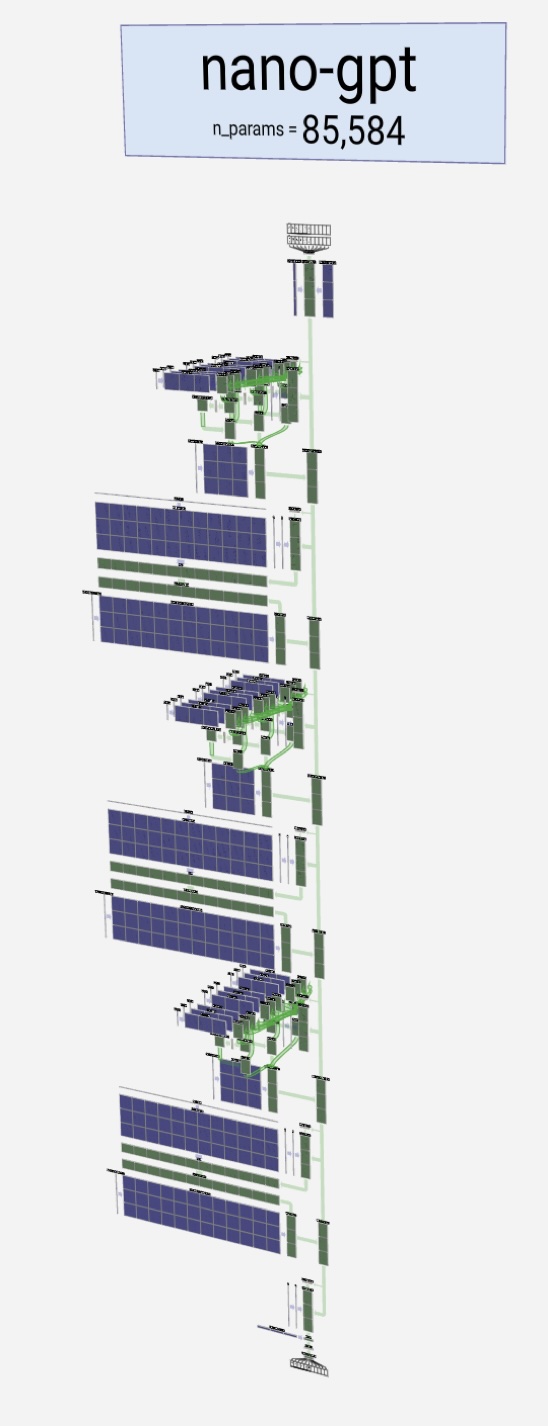
It's difficult to appreciate the multi-head attention and multiple transformer layers in the original diagram. Brendan Bycroft provides a neat visualization tool at https://bbycroft.net/llm that shows these features in greater detail. A snapshot is shown on the right for Karpathy's nanoGPT.
More to come!